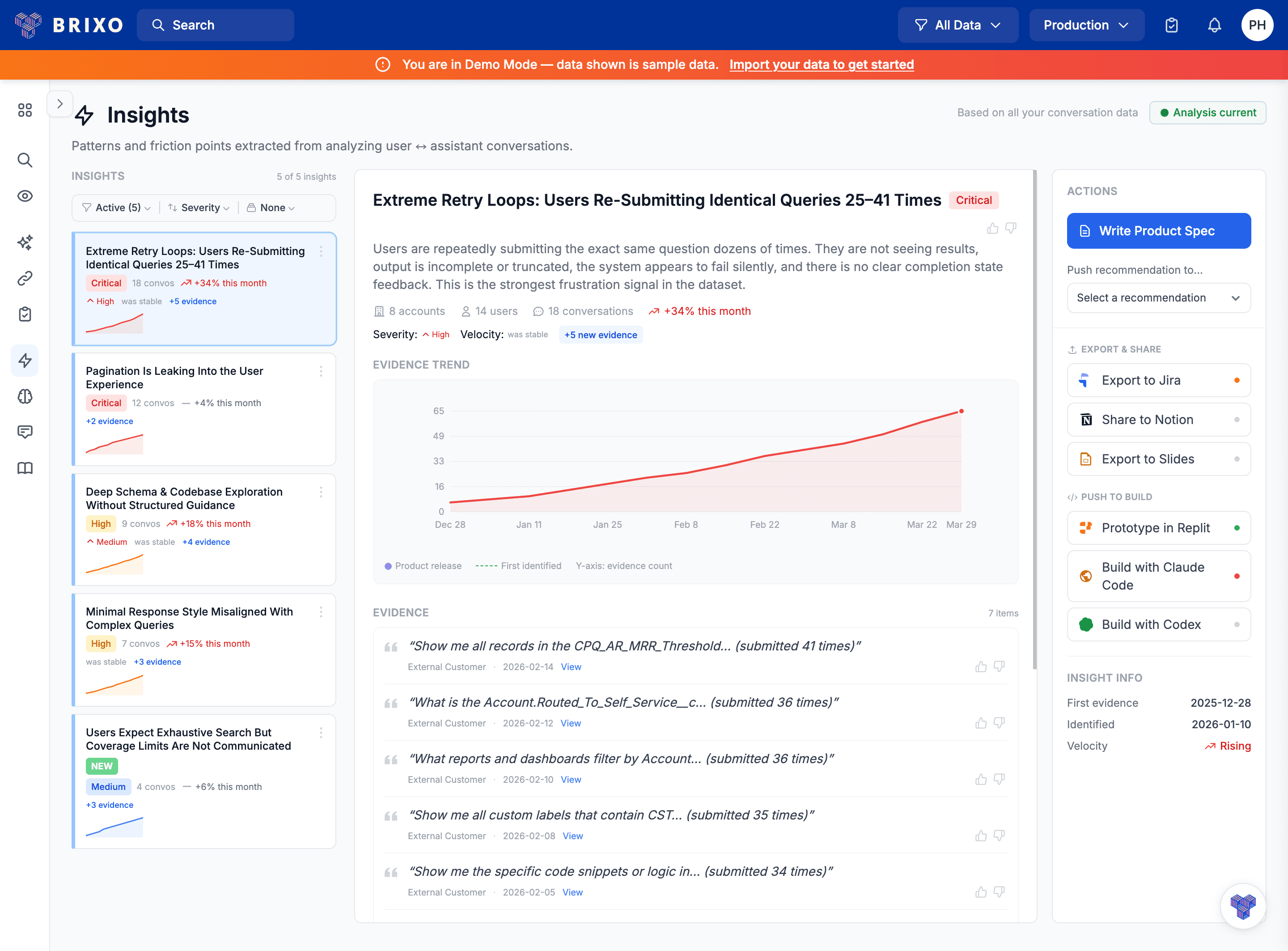
How Do I Measure Chatbot Success?
Measure chatbot ROI with task completion rate, deflection rate, user satisfaction, and cost savings. Learn which metrics actually predict chatbot success.
How to Measure Chatbot Success
Chatbot success is measured by deflection rate (percentage of issues resolved without human help), task completion rate, user satisfaction (CSAT), and cost per resolution. Engagement metrics like message count and session duration are misleading — high engagement often means users are frustrated, not satisfied. The 7 essential metrics are deflection rate, task completion rate, user satisfaction, first contact resolution, escalation rate, cost per resolution, and average handle time.
The Problem with Typical Chatbot Metrics
Most teams start by tracking vanity metrics that mislead: "10,000 chatbot conversations!" (Were they successful?), "Average session: 5 minutes" (Because users were frustrated?), "8 messages per conversation" (Rephrasing the same question?). The metrics that actually matter are different: Did the chatbot solve the user's problem? How satisfied were users? How much money did it save vs human support? Reality check: High engagement can mean your chatbot is confusing. Long sessions can mean it's not giving clear answers. Track outcomes, not activity.
The 7 Essential Chatbot Success Metrics
Measure deflection rate (percentage of issues resolved without human help), task completion rate, user satisfaction, and cost per resolution. Don't rely on engagement metrics -- users might engage frequently because your chatbot keeps failing.
1. Deflection Rate (Primary KPI)
Definition: Percentage of support requests fully resolved by the chatbot without human escalation. This directly measures your chatbot's business impact -- it's the metric executives care about. Formula: Deflection Rate = (Chatbot-resolved issues / Total support requests) x 100 Example: January had 5,000 total tickets, 3,400 chatbot resolved, 1,600 human escalations. Deflection Rate = 68%. Benchmarks by type: FAQs/simple support: 75-85%. Tier 1 support (password resets, tracking): 65-80%. Tier 2 (troubleshooting, billing): 40-60%. Tier 3 (technical, complex): 15-30%. Pro tip: Don't chase 100% deflection. Some issues should go to humans. Deflection below 50% means the chatbot isn't handling its scope. Deflection above 90% might mean it's giving bad answers instead of escalating.
2. Task Completion Rate
Definition: Percentage of conversations where the user successfully accomplished their goal. Deflection alone can be misleading -- users might not escalate but also not get their problem solved. What counts as completed: User explicitly confirms ("Thanks, that solved it!"), user takes the suggested action, user rates positively, or conversation ends with resolution rather than abandonment. Benchmarks: Simple queries (password reset, order tracking): above 85%. Moderate queries (billing, how-to): above 65%. Complex queries (technical troubleshooting): above 45%.
3. User Satisfaction Score (CSAT)
Definition: How satisfied users are with the chatbot interaction. You can "deflect" a ticket but leave the user frustrated. CSAT measures quality of experience. How to measure: Post-chat survey ("How would you rate this interaction?" 1-5 stars), simple feedback ("Was this helpful?" thumbs up/down), or CSAT question (1-5 scale). Benchmarks: Excellent: above 4.2/5.0 or above 80% positive. Good: 3.8-4.2 or 70-80% positive. Needs improvement: below 3.8 or below 70% positive. Compare CSAT for chatbot vs human support. If the gap is greater than 1.0, users significantly prefer humans and your chatbot needs work.
4. First Contact Resolution (FCR)
Definition: Percentage of issues resolved in the first chatbot interaction with no follow-up needed. If users have to return with the same issue, your chatbot's first answer didn't actually help. What lowers FCR: Generic answers that don't solve specific cases, users misunderstanding instructions, chatbot lacking context, or underlying product bugs the chatbot can't fix. Benchmarks: Excellent: above 80%. Good: 65-80%. Poor: below 65%. Bad example: User asks "How do I cancel my subscription?" Bot says "You can cancel in account settings." User returns: "I don't see that option." Good example: Same question, bot responds: "To cancel: 1) Click your profile 2) Select 'Billing' 3) Scroll to bottom 4) Click 'Cancel Subscription'. It's the red button below your payment info." User cancels successfully.
5. Escalation Rate
Definition: Percentage of chatbot conversations transferred to a human agent. Shows the boundary of your chatbot's capability and affects cost savings. What triggers escalation: User requests human, chatbot detects complex issue, repeated negative feedback, confidence below threshold, or conversation exceeds turn limit. Benchmarks: Tier 1 support chatbot: 15-30%. Sales chatbot: 50-70% (expected -- humans close deals). FAQ chatbot: below 10%. Technical support: 40-60%. Track why escalations happen. If 28% are "can't find answer," expand your knowledge base. Monitor for red flags: escalation rate increasing means performance degrading.
6. Cost per Resolution
Definition: Total cost to resolve a support issue via chatbot vs human agent. This is your ROI metric. Chatbots only make business sense if they're cheaper and effective. Chatbot cost formula: (LLM API costs + infrastructure + maintenance) / Resolutions Human cost formula: (Agent salary + benefits + overhead + tools) / Resolutions handled Example: AI Chatbot costs $0.39 per resolution (at 70% success rate). Human agent costs $4.67 per resolution. Savings: $4.28 per resolution. At 3,500 resolutions/month: $14,980 savings, 499% ROI.
7. Average Handle Time (AHT)
Definition: How long it takes the chatbot to resolve an issue (time or number of turns). Faster resolution means better UX and lower costs for usage-based APIs. Benchmarks: Simple issues: under 2 minutes, under 4 turns. Moderate issues: 3-6 minutes, 6-10 turns. Complex issues: 7-12 minutes, 12-20 turns. Red flags: AHT increasing over time means performance degrading. AHT over 20 turns means chatbot stuck in loops. AHT much longer than human means chatbot is inefficient for that issue type.
Creating Your Chatbot Dashboard
Daily monitoring: Check deflection rate (primary KPI), CSAT score (quality check), and critical errors (hallucinations, offensive responses). Set alerts for deflection drops over 10% day-over-day, CSAT below 3.5/5, or escalation spikes over 20%. Weekly reviews (every Monday): Review deflection by issue category, analyze top 10 escalation reasons, read 20-30 low-rated conversations, check repeat contact patterns, compare AHT to baseline. Take action on the top 3 failure modes. Monthly business reviews: Present key metrics, wins, areas needing attention, and next month's action items to stakeholders. Include deflection rate, CSAT, cost savings, and ROI.
Chatbot Success by Use Case
Customer support chatbot: Focus on deflection rate (65-75%), task completion (70%+), CSAT (4.0+), and monthly cost savings. Key areas: first contact resolution, escalation reasons. Sales qualification chatbot: Focus on lead capture rate (60%+), qualified lead rate (40%+), meeting booking rate (20%+), lead quality score (7/10+). Key areas: conversation-to-conversion, objection handling. FAQ/self-service chatbot: Focus on deflection rate (80%+), task completion (85%+), fallback rate (below 3%), CSAT (4.3+). Key areas: knowledge coverage, intent recognition. Appointment booking chatbot: Focus on booking completion rate (55%+), no-show rate (below 15%), time saved, CSAT (4.2+). Key areas: form completion friction, calendar integration reliability. Common Measurement Mistakes: Only measuring volume ("10,000 conversations" doesn't tell you if they were successful -- pair volume with quality metrics). Not segmenting by issue type (averaging all issues hides what your chatbot handles well vs poorly). Ignoring user sentiment (high deflection with low CSAT means users are frustrated but not escalating). Not comparing to humans (without a baseline, you can't measure improvement).